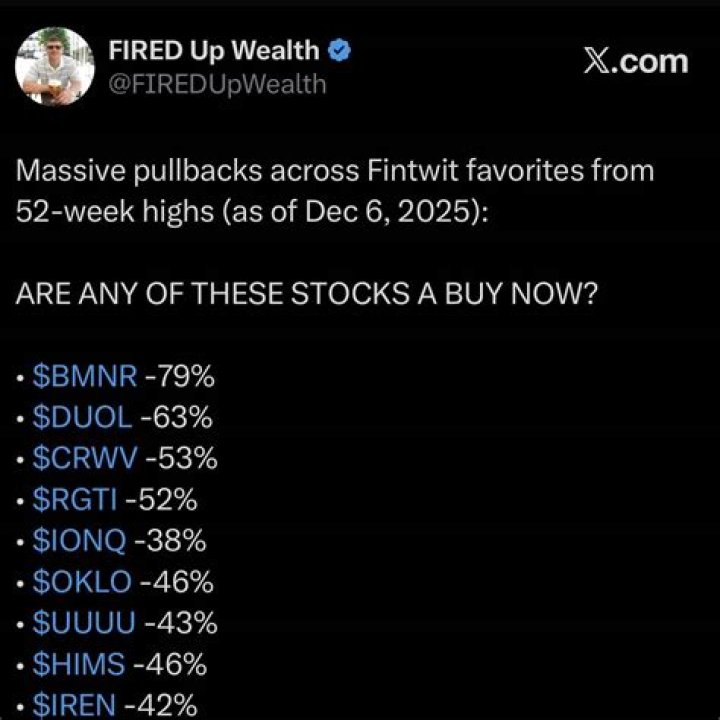
Can't grep price in downloaded webpage
By Sarah Smith
Using wget I downloaded this webpage:
With the command:
RobWebsiteAddress=""
DownloadName="Ejoyous1"
wget -O- -q --user-agent=AGENT "$RobWebAddress" > "$DownloadName"When I try to open the file in gedit it goes crazy.
When I use:
grep -i 23.31 Ejoyous1 | wc 0 0 0The price isn't found. If I grep on the word price I get one long line of 146,329 characters returned which is probably what drove gedit crazy:
$ grep -i price Ejoyous1 | wc 1 6292 146329Within the .5 MB file is some hints:
$ grep -i necolas Ejoyous1
/*! normalize.css v8.0.0 | MIT License | */As you can tell this is from Walmart's website. I have no problem getting Costco's pricing and Ikea's pricing by simply downloading the webpage with wget and grepping it. I also have no problem viewing the downloaded files from Costco or Ikea with gedit.
How can I interpret this language if it's a derivative of HTML? What tools should I use? Any clues to get on the right path?
22 Answers
Many pages download content separately from the main page (from a separate "file"), so there is nothing to grep in the file you're downloading with wget. Firefox runs the javascript, which allows it to download the content. You can press (Ctrl+Shift+C) to see the javascript console. Click "Network" then reload the page to see what connections it's making. One of the connections is a json "file" called price-offer.
It's possible to get at the data if you're able to figure out where the content is located. Otherwise, you'd have to execute the javascript, like Firefox does. However, it's not as straightforward as just providing a URL. You also have to send data to the server to get the information you want. (The API cmak.fr describes.)
I found I could open the web page with Firefox which has a "Save As" .html option. The resulting save file could then be grepped for the price.
This works because the browser adds the extra information (from json) to the page before saving it. To skip manually clicking around the GUI, you can download the page with Chromium. (Firefox can be used as well, but looks more complicated – MDN Headless Mode.)
chromium-browser --headless --disable-gpu --dump-dom "" > example.htmlThen grep for the price:
sed -i.bak -Ee 's@,@,\n@g' example.html
grep -wEe '"price"\:[0-9]+\.[0-9]+' example.html Price information is displayed in the webpage by a js script using API and json
That is why the price text is not present in the source code of the webpage
A browser web dev tools will show that the price -and more info as stock- comes from a json response
Since those kind of process can be secured by authentication and cookies and since wget and curl cannot download the json file, an idea will be to register and use the Wallmart API
But it seems that the API is for partners vendors
Another idea would be to reverse the public Webpage build process to send a well formed API request...
2